Breaking Down the AI Transformer
The study “Attention Is All You Need” is a groundbreaking paper on the enhancement of the large language model (LLM)’s self-attention mechanism.
The study introduces the transformer, a new piece of AI model architecture. This new building block uses an attention mechanism to model input and output dependencies.
I wanted to create a beginner's guide to the architecture for anyone entering this field with little knowledge of the topic.
Let’s just call this a thorough but simplified version of the process.
The Transformer
The transformer model was developed to address the problem of sequence transduction. Essentially, the transformer's job is to translate an input sequence into an output sequence.
This could be compared to a human reading a page of text, then being asked to summarize the passage. To complete a successful summary, we would pick out the most important parts of the text and cut out any filler. These decisions are made through natural critical thinking. The transformer enables the model to “think” and predict using logic and probability, grounded in human linguistics.
This allows models to complete unsupervised fine-tuning much faster than RNNs, as the attention mechanism enables parallel data processing.
Transformers change an input sequence into an output sequence by learning the context of the input.
A major part of the model revolves around the attention mechanism, which allows the model to determine which data is the most relevant when processing an answer. It prioritizes information through predictors and assigns relevance by placing different weights to different portions of the input.
Below is the transformer architecture
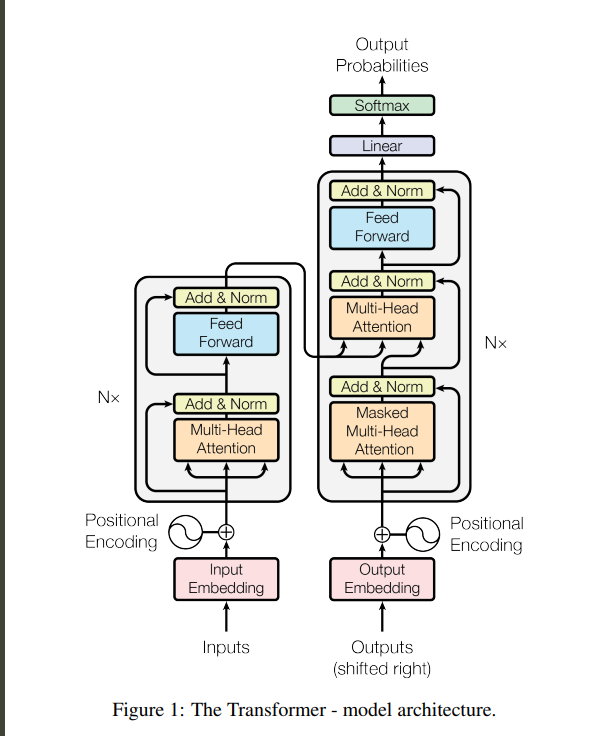
Breaking Down the Diagram
The Beginning.
Before anything happens, the tokenization process must occur. That’s when the input text is broken down by words or parts of words classified as tokens. Models don’t understand words or letters, so the words you input are broken up into tokens that must be converted to numerical representations (vectors).
Once the tokens are converted into vectors, the model can understand the input.
The first major step in this diagram is Embedding.
Embedding allows the model to relate words to each other. I like to think of it as a 3D graph where each word has a value, and how closely the words are related determines the space between them. The words that are more similar to each other have less space between them. This creates a visual and numerical representation of vocabulary.
This method processes the input text and allows the model to understand relationships between words.
Like a human, the model must create an environment that allows it to “think.” We read and retain the information we learn in our minds, then we form relationships between words with little effort. When someone says “computer” and “laptop,” we know those words are similar and why.
Positional encoding
Positional encoding helps the model understand word positions. Though the model can turn tokens into vectors, it does not naturally understand or process the order in which those words were written.
This is an issue when trying to understand any context within a sentence.
If you have the sentence
My dog loves my cat.
It matters how the words are ordered because just switching two words changes the whole meaning.
My cat loves my dog.
As shown in the architecture diagram, this process is injected after the input embedding.
Next is Layer Normalization (Norm)
Layer normalization is used to prevent issues that training models can encounter, such as exploding and vanishing gradients and overfitting.
Add (Residual connection)
Add allows the original input to be kept without being changed, so the process doesn’t lose sight of the original and degrade. This step allows the input to skip the layer operations and apply itself directly to the output.
Feed-forward network
Once the tokens are defined contextually, they must be defined independently. The model uses previously learned context to assign meaning to each token and can predict the next word based on probability.
Attention
The attention mechanism has been around for more than a few years; it is a groundbreaking architectural concept in the AI world. The attention mechanism allows the deep learning model to focus on different parts of the input with varying levels of importance. The mechanism prioritizes the most relevant data by computing the relevance of words or parts of words by assigning weights that reflect the importance of each token within the context of the input.
1) Scaled Dot-Product
Each word is represented by a vector of numbers, also called an embedding. It is easy to understand the concept that a word can be represented by a number, but the embedding allows the machine to create contextual representations of words within the text and how they relate to each other through vectors as well.
The scaled dot product determines how the words in the input are relevant to each other and how important they are in the sequence.
You can see in the first diagram below that the inputs are query(q), key(k), and value(v)
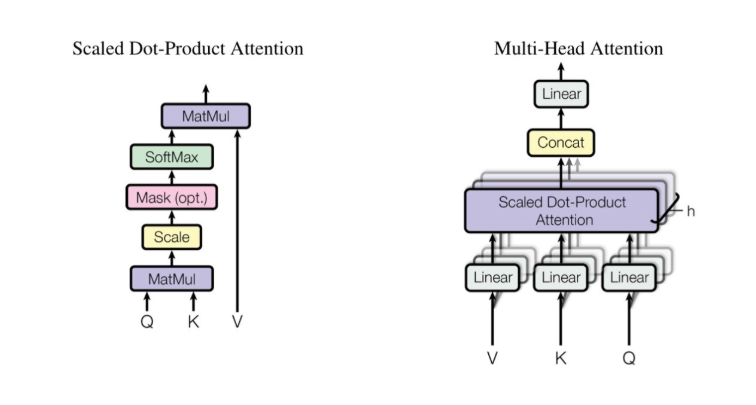
2) Multi-Head Attention
A multi-attention head is when the attention mechanism repeats its calculations multiple times in parallel. The attention separates the query(Q), key(K), and value(V) parameters, which are all sent through separately, and then combined to produce the attention score. The attention score is how the model ranks the most important words or letters within a sentence.
3) Softmax
Softmax functions are used to convert the decoder output and predict next-token probabilities. The same weight matrix is used between the two embedding layers and the pre-softmax linear transformation.
Softmax converts a vector into a probability distribution.
Linear Layer produces the output.
Output Embedding predicts the next word in a sentence and stores the predictions so it can suggest another prediction.
This process continues.
If you would like to know more, check out the study it originated from. Attention Is All You Need, to learn more about the mathematical functions, the code, and the experiments they completed.
Below is a list of important terms. If you would like to continue learning, I recommend looking at actual studies or articles on the topic rather than relying on AI to explain it, because, more often than not, AI doesn’t define or explain these concepts correctly.
#Transformer
#Tokenization
#Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs)
#Embedding
#Positional encoding
#Layer normalization
#Residual connection
#Feedforward network
#Attention
#Linear layer
#Output embedding
#exploding and vanishing gradients
#overfitting
#Scaled dot-product
#Multi-head attention
#Softmax